本文共 2273 字,大约阅读时间需要 7 分钟。
什么?!颜值“客观化”要进行实质性推进了?
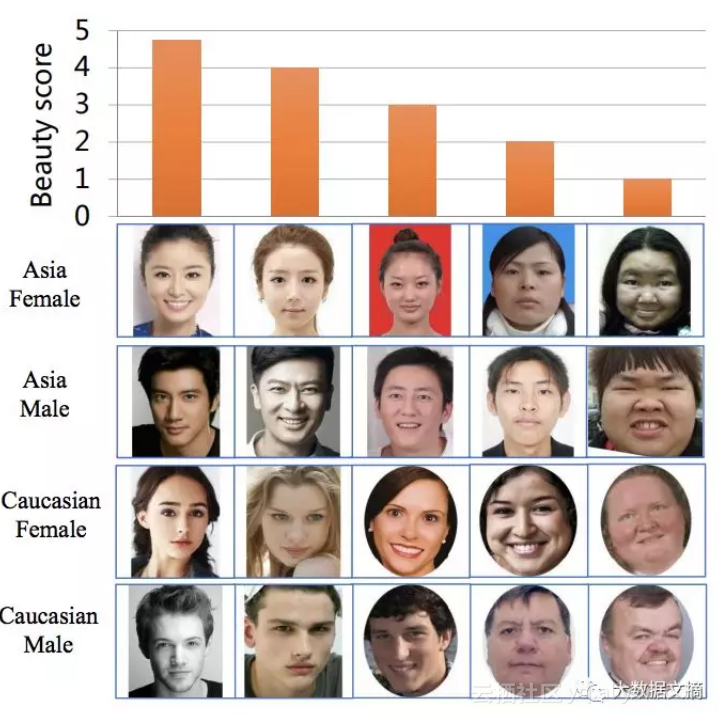
几个月前,华南理工大学发布了一篇关于“颜值评估”的论文及其数据集。
这个数据集包括5500人,每人的长相被从1-5分进行打分。
数据的下载地址如下:
https://github.com/HCIILAB/SCUT-FBP5500-Database-Release
让文摘菌来举个栗子,你就知道这个数据是咋回事啦。
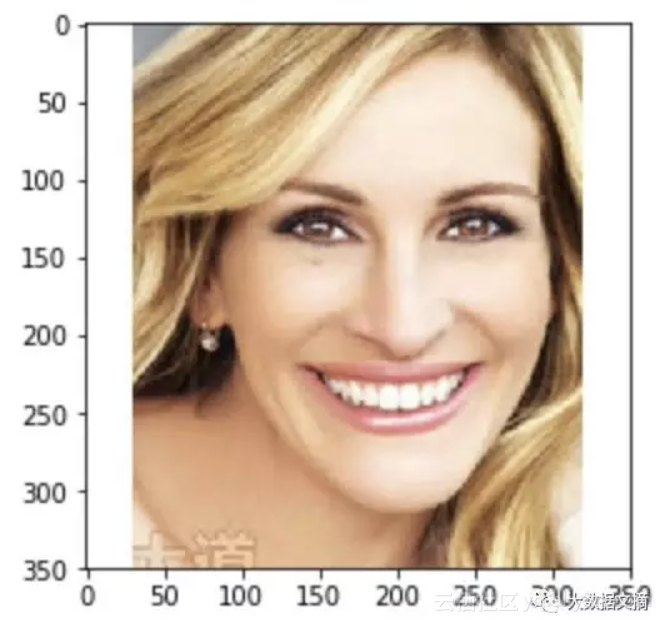
数据集中还包括一些明星。这张Julia Roberts的照片平均得分为3.78:
这张以色列著名模特Bar Refaeli的照片获得了3.7分。
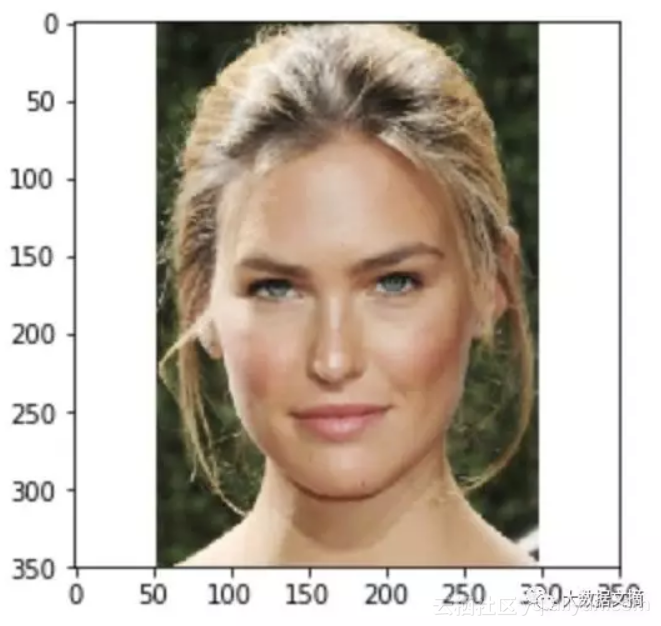
这些分数可能看起来有点低,但3.7分已经代表你的颜值比数据集中约80%的人高了。
在这个数据集上,作者训练了多个模型,试图根据人脸图片评估颜值。
在这篇文章中,我要复现他们的结果,并测一下自己的颜值。
原始论文构造了一系列不同的模型,包括使用人工构造特征的经典ML模型和3种深度学习模型:AlexNet、ResNet18和ResNext50,我希望尽可能简化我的工作(我不想从头开始训练Resnet神经网络模型),我想对现有的模型进行调优。在keras中,有一个称为application的模块,它包含各种不同的预训练过的模型。resnet50就是其中之一。 不幸的是,在keras.applications中没有ResNet18或ResNext50,所以我不能完全复现研究人员之前的研究过程,不过利用resnet50也能足够接近之前的工作。
from keras.applications import ResNet50
ResNet是一个由微软开发的深度卷积网络,它赢得了2015 年的ImageNet图像分类任务竞赛。
在keras中,当我们初始化resnet50模型时,我们创建了一个ResNet50结构的模型,并且下载了在ImageNet数据集上训练的权重。
论文的作者没并有提到他们究竟是如何训练模型的,不过我会尽力做到最好。
我想删除最后一层(“softmax”层)并添加一个没有激活函数的全连接层来做回归。
resnet = ResNet50(include_top=False, pooling=’avg’)model = Sequential()model.add(resnet)model.add(Dense(1))model.layers[0].trainable = Falseprint model.summary()# Output:Layer (type) Output Shape Param # ================================================================= resnet50 (Model) (None, 2048) 23587712 _________________________________________________________________ dense_1 (Dense) (None, 1) 2049 ================================================================= Total params: 23,589,761 Trainable params: 23,536,641 Non-trainable params: 53,120
你可以看到我把第一层(resnet模型)设置为不可训练的,所以我只有2049个可训练的参数,而不是23589761个参数。
我的计划是训练最后的全连接层,然后以较小的学习率训练整个网络。
model.compile(loss='mean_squared_error', optimizer=Adam())model.fit(batch_size=32, x=train_X, y=train_Y, epochs=30)
之后,我将第一层改为可训练的,编译模型,并再把模型训练30轮。
在这里,train_X代表照片,也就是形状为(350,350,3)的numpy矩阵,train_Y是图像被标记的分数。
结论
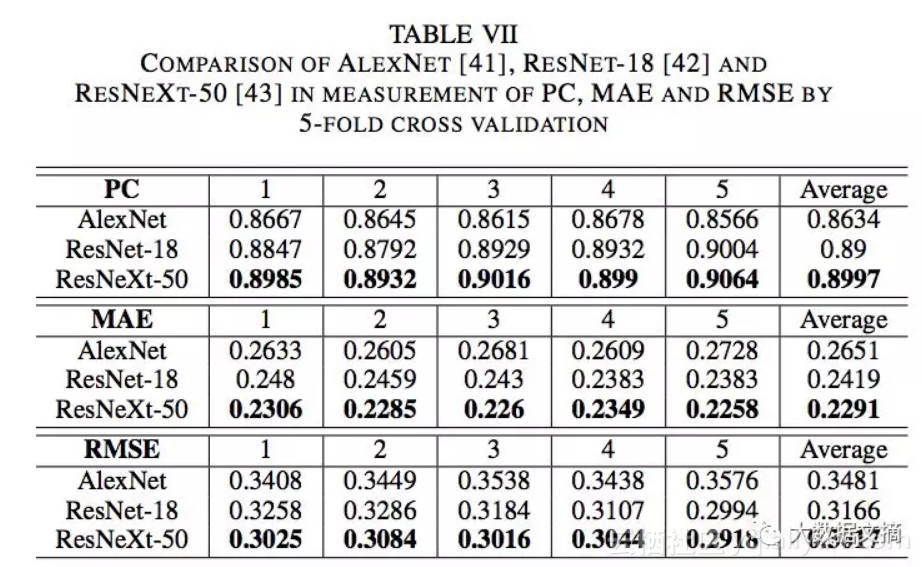
论文使用2种方法训练模型:5折交叉验证和以6:4的比例将数据集分割为训练集和测试集。他们使用皮尔逊相关系数(PC),平均绝对误差(MAE)和均方根误差(RMSE)来测评估模型的结果。以下是他们使用5折交叉验证得到的结果:
这些是他们使用6:4分割数据集获得的结果:
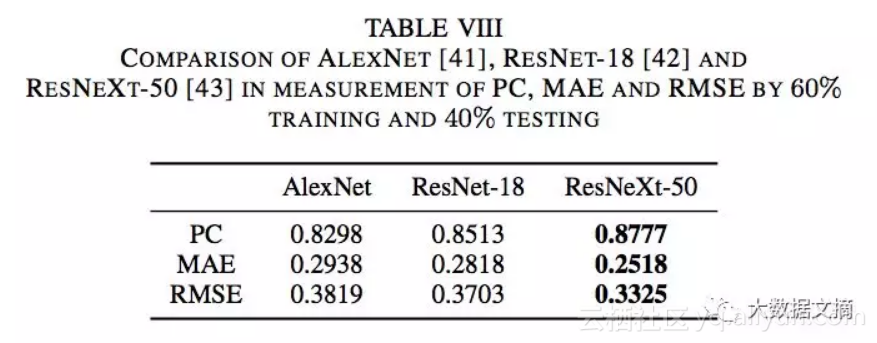
我以8:2的比例分割数据集,所以它类似于执行1折交叉验证。
我得到的结果如下:
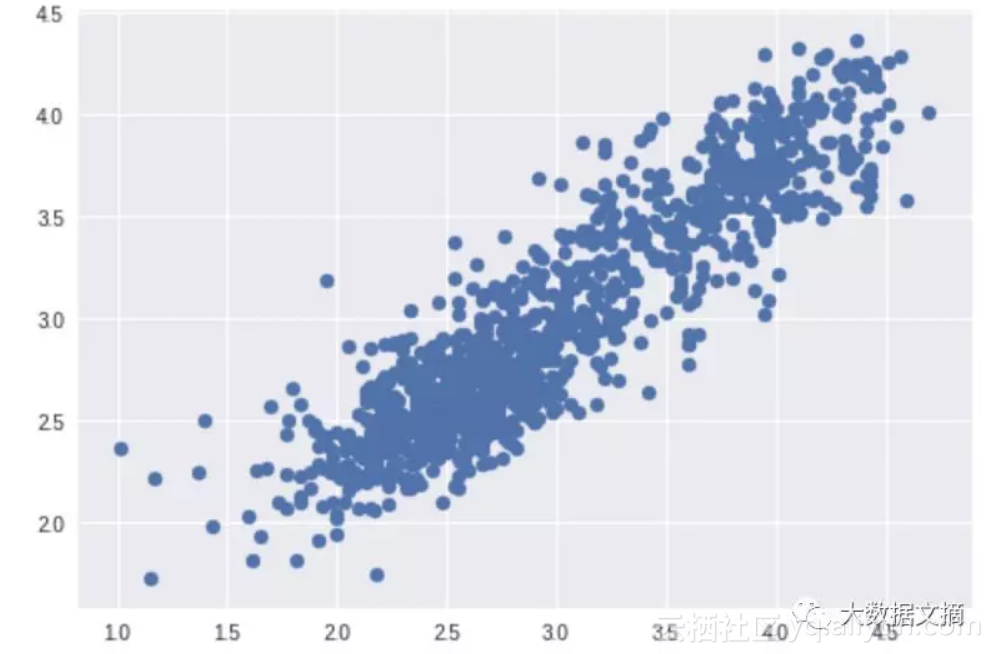
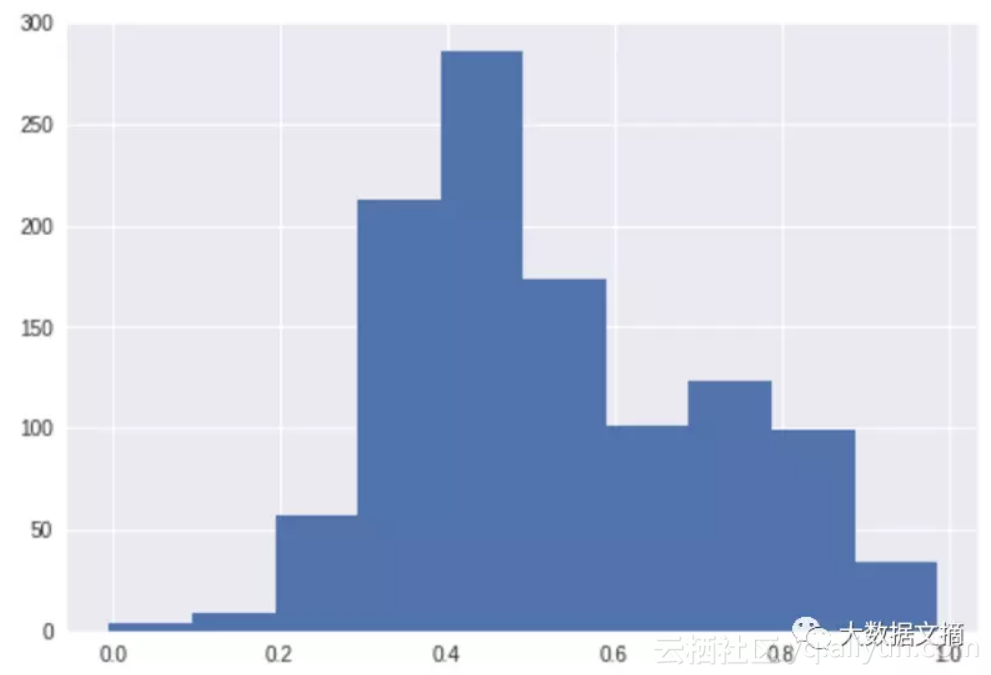
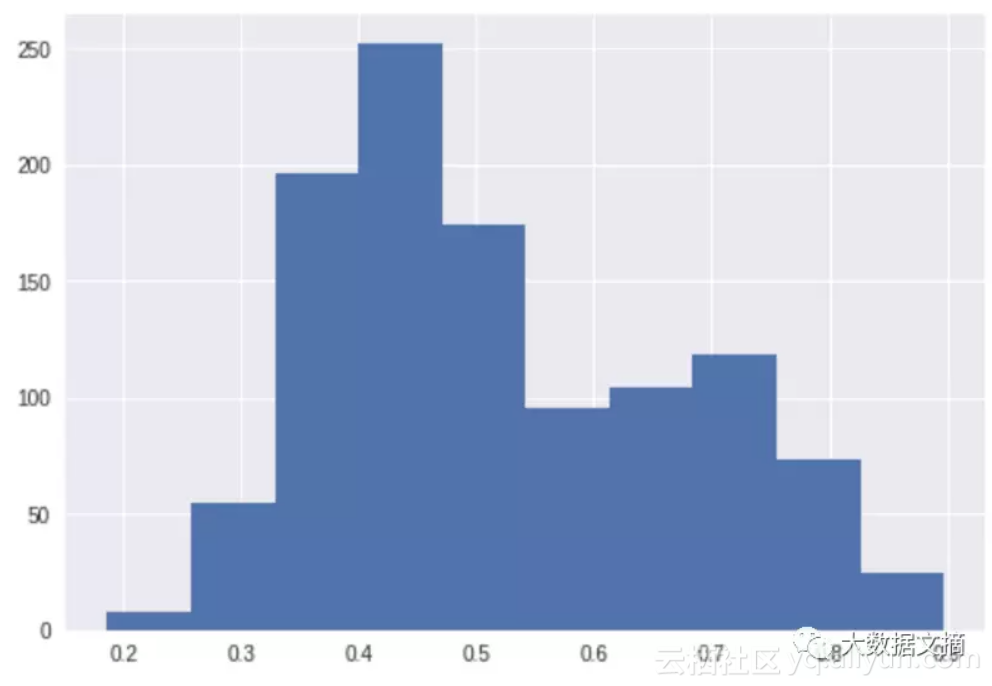
非常好的结果。另外,也可以看看散点图和直方图:
原始分数分布(标准化后的):
预测分数分布(标准化后的):
结果看起来不错。现在在我身上试试这个这个神经网络。我首先使用这张照片:
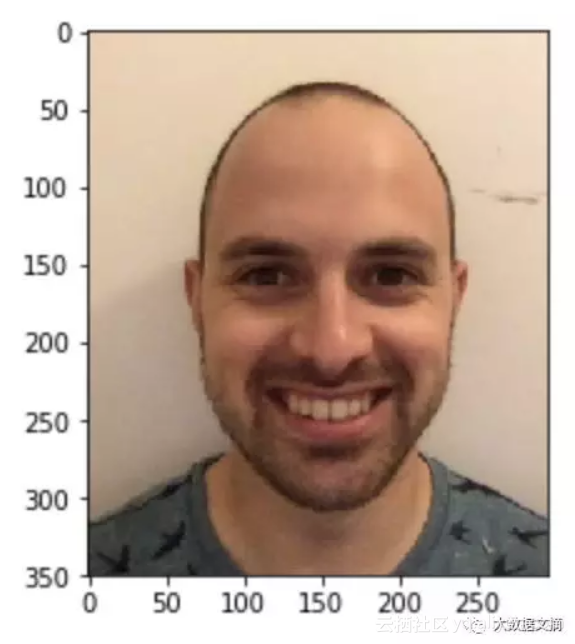
我的分数是2.85,这意味着我的颜值比数据集中52%的人高。不得不说我有点失望,我以为我的分数会高一些,所以我试图提高我的分数。
我拍了很多照片,最终我得到了3.15分,这意味着我比数据集中64%的人更具吸引力。

这比之前好很多了,不过我必须诚实地说,我希望还能更高:)
最后一点,我使用Google Colaboratory构建和调整了这个模型,简而言之,Google Colaboratory能为你提供一个免费使用GPU的python notebook!
原文发布时间为:2018-04-24
本文作者:文摘菌
本文来自云栖社区合作伙伴“”,了解相关信息可以关注“”。
转载地址:http://itezx.baihongyu.com/